
Incremental Learning in Diagonal Linear Networks
Updated: 2023-07-31 22:55:03
Diagonal linear networks (DLNs) are a toy simplification of artificial neural networks; they consist in a quadratic reparametrization of linear regression inducing a sparse implicit regularization. In this paper, we describe the trajectory of the gradient flow of DLNs in the limit of small initialization. We show that incremental learning is effectively performed in the limit: coordinates are successively activated, while the iterate is the minimizer of the loss constrained to have support on the active coordinates only. This shows that the sparse implicit regularization of DLNs decreases with time. This work is restricted to the underparametrized regime with anti-correlated features for technical reasons.
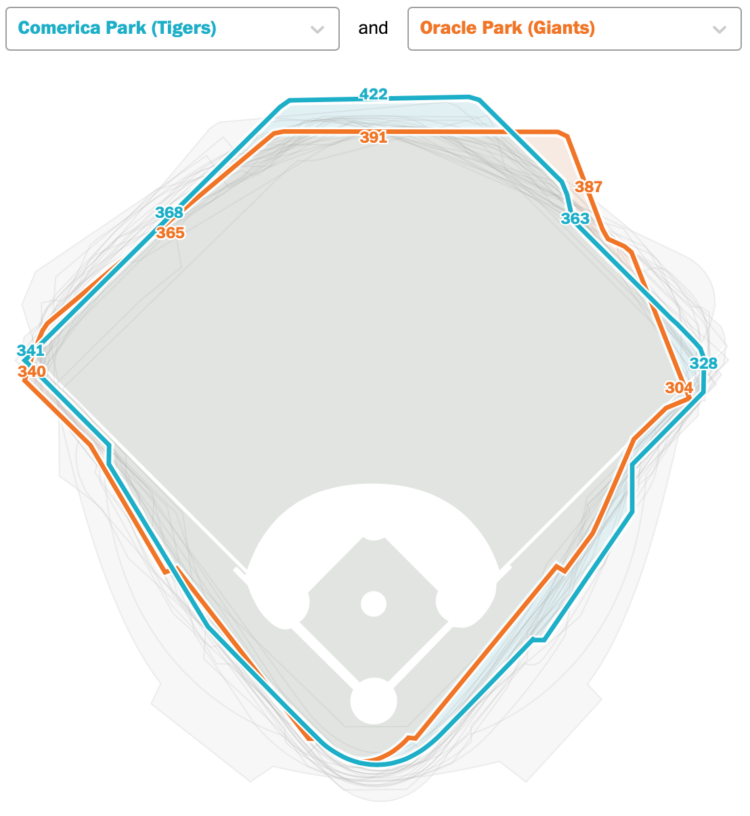 Membership Courses Tutorials Projects Newsletter Become a Member Log in Comparing home run in distance different stadiums July 31, 2023 Topic Infographics baseball home run Washington Post In Major League Baseball , a player hits a home run when the ball flies over the outfield fence . However , the distance between the hitter and the outfield fence varies by stadium , which means a home run in one stadium might not be far enough for a home run in a different stadium . For The Washington Post , Kevin Schaul made a thing that lets you compare stadiums Related Investors bought up a lot of houses in 2021 Senators and Reps whose voting doesn’t quite match the constituent’s Issues Democratic hopefuls are talking about on social media Become a . member Support an independent site . Make great
Membership Courses Tutorials Projects Newsletter Become a Member Log in Comparing home run in distance different stadiums July 31, 2023 Topic Infographics baseball home run Washington Post In Major League Baseball , a player hits a home run when the ball flies over the outfield fence . However , the distance between the hitter and the outfield fence varies by stadium , which means a home run in one stadium might not be far enough for a home run in a different stadium . For The Washington Post , Kevin Schaul made a thing that lets you compare stadiums Related Investors bought up a lot of houses in 2021 Senators and Reps whose voting doesn’t quite match the constituent’s Issues Democratic hopefuls are talking about on social media Become a . member Support an independent site . Make great Membership Courses Tutorials Projects Newsletter Become a Member Log in Barbie and Oppenheimer themes for charts in R July 28, 2023 Topic Software Barbie ggplot Matthew Jané Oppenheimer R theme Matthew Jané made a small R package called Theme Park which is meant to supply movie-based themes for ggplot . For now , it just has Barbie and Oppenheimer . themes Related xkcd-style charts in R , JavaScript , and Python Movie quotes as charts , poster edition Famous Movie Quotes as Charts Become a . member Support an independent site . Make great charts . See what you get Projects by FlowingData See All Data Underload 18 Sleep Schedule According to WebMD , for 1- to 4-week-olds : Since newborns do Social Media Usage by Age Here’s the breakdown by age for American adults in 2021, based on data
Membership Courses Tutorials Projects Newsletter Become a Member Log in Barbie and Oppenheimer themes for charts in R July 28, 2023 Topic Software Barbie ggplot Matthew Jané Oppenheimer R theme Matthew Jané made a small R package called Theme Park which is meant to supply movie-based themes for ggplot . For now , it just has Barbie and Oppenheimer . themes Related xkcd-style charts in R , JavaScript , and Python Movie quotes as charts , poster edition Famous Movie Quotes as Charts Become a . member Support an independent site . Make great charts . See what you get Projects by FlowingData See All Data Underload 18 Sleep Schedule According to WebMD , for 1- to 4-week-olds : Since newborns do Social Media Usage by Age Here’s the breakdown by age for American adults in 2021, based on data , Membership Courses Tutorials Projects Newsletter Become a Member Log in Members Only Visualization Tools and Learning Resources , July 2023 Roundup July 27, 2023 Topic The Process roundup Welcome to The Process where we look closer at how the charts get made . This is issue 249. Thanks for supporting this small visualization corner of the internet . I’m Nathan Yau , and throughout the month I collect tools and resources to help you make better charts . This is the good stuff for . July To access this issue of The Process , you must be a . member If you are already a member , log in here See What You Get The Process is a weekly newsletter on how visualization tools , rules , and guidelines work in practice . I publish every Thursday . Get it in your inbox or read it on FlowingData . You
, Membership Courses Tutorials Projects Newsletter Become a Member Log in Members Only Visualization Tools and Learning Resources , July 2023 Roundup July 27, 2023 Topic The Process roundup Welcome to The Process where we look closer at how the charts get made . This is issue 249. Thanks for supporting this small visualization corner of the internet . I’m Nathan Yau , and throughout the month I collect tools and resources to help you make better charts . This is the good stuff for . July To access this issue of The Process , you must be a . member If you are already a member , log in here See What You Get The Process is a weekly newsletter on how visualization tools , rules , and guidelines work in practice . I publish every Thursday . Get it in your inbox or read it on FlowingData . You Sarah Bell made an animated version of John Snow’s classic map from 1854.…Tags: animation, cholera, John Snow, Sarah Bell
Sarah Bell made an animated version of John Snow’s classic map from 1854.…Tags: animation, cholera, John Snow, Sarah Bell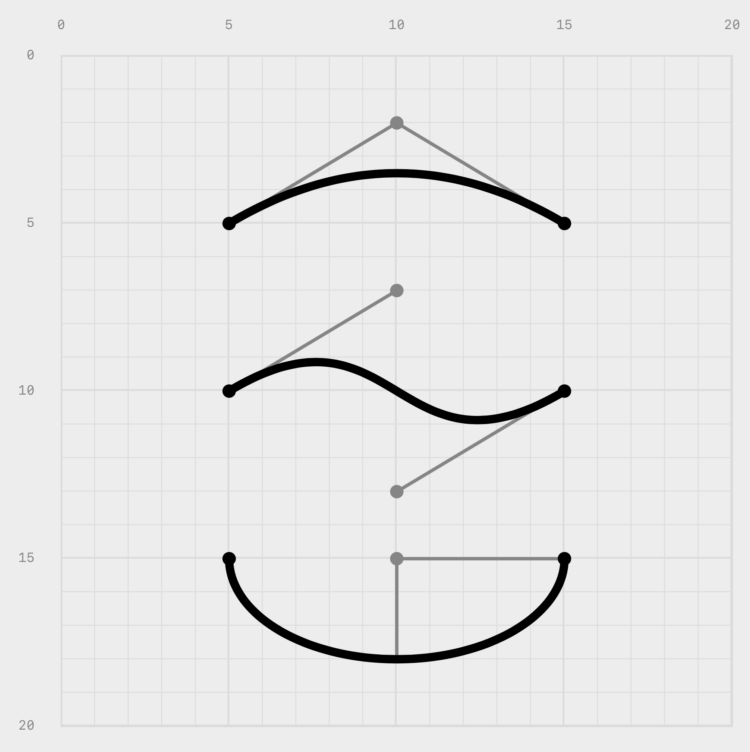 , Membership Courses Tutorials Projects Newsletter Become a Member Log in Understanding the SVG path element , a visual guide July 20, 2023 Topic Coding Nanda Syahrasyad paths SVG The SVG path element can be useful for drawing regular and irregular shapes . However , if you just look at how a path is defined , it’s not entirely clear how to use it . Nanda Syahrasyad made a visual guide to help you figure it out Related Visual Guide to the Financial Crisis Visual Guide to General Motors’ Financial Woes Visual guide for the fires in Australia Become a . member Support an independent site . Make great charts . See what you get Projects by FlowingData See All Mapping the Spread of Obesity A look at the rise for each state over three decades , for men and . women Who Still Smokes Two decades
, Membership Courses Tutorials Projects Newsletter Become a Member Log in Understanding the SVG path element , a visual guide July 20, 2023 Topic Coding Nanda Syahrasyad paths SVG The SVG path element can be useful for drawing regular and irregular shapes . However , if you just look at how a path is defined , it’s not entirely clear how to use it . Nanda Syahrasyad made a visual guide to help you figure it out Related Visual Guide to the Financial Crisis Visual Guide to General Motors’ Financial Woes Visual guide for the fires in Australia Become a . member Support an independent site . Make great charts . See what you get Projects by FlowingData See All Mapping the Spread of Obesity A look at the rise for each state over three decades , for men and . women Who Still Smokes Two decades